Introduction
NB: this article is quite a long read with discussions around choices and woes related to using PHP in production. In case you're just interested in a short description we invite you to have a look at the project README on Github.
Frameworks are great and in that regard, both Symfony and Laravel are awesome projects.
However, I don't know about you but something I love about PHP (which is actually even more true for JavaScript) is that the language is very flexible.
Want to never use a class, ever? You can if you want to.
Want to output any content type and data in a few lines of code? You could just set the content type with the header function and print or echo the whole content afterwards and that would work.
Want to reuse an old PHP 3.0 file that has a bunch of functions in it? You can. Just import it. It still works (well, for the most part it should).
Frameworks by definition not only take care of most of the boilerplate but also force you to work a certain way. And that's not necessarily bad in itself although it's unavoidably adding clutter, dependencies and importing code that you might not actually be using.
In some programming languages, unused code import would have a low impact on general performances, if done well. PHP however, has an execution model that is pretty much unique in the current ecosystem and we'll try explaining how it's amplifying the issue of having a lot of initialization code.
The current article might look very opinionated but we just wanted to show a different perspective and relate current times to back when PHP was, in all intent and purposes, freedom.
Teams should do what works best for teams, a unified worflow and test-driven programming would definitively be a plus. But what if you personally want to whip out a quick REST API or a simple backend for a single purpose that would still scale very well?
The PHP Interpreter
The PHP interpreter is currently almost always used a certain way, which consists in having a web server call a CGI handler to process the PHP and then pass the result on to the clients.
The CGI handler in turns calls the PHP interpreter on the code, which runs the code in one sweep, outputs the result, then exits.
In practice PHP is rarely used strictly as a standard CGI, but in any cases we're still invoking the interpreter on the entirety of the PHP file that was requested, every time it is requested.
This results in the main weakness of using PHP in production: it has to recreate its whole context for every single request.
How is that specific to PHP you ask? Well let's look at a Java Spring Boot application for comparison. The app itself is packaged in a jar file that you run in a JVM. The app then listens to a specific TCP port for HTTP requests.
The most common use case is then to put a web server in front of it and proxy requests to the Java app.
The JVM will be a single process called "java" ("java.exe" or "javaw.exe" on Windows) that has to be and stay in memory in order for the app to be able to answer requests.
With PHP there is no such process in memory. There might be a process facilitating the creation of CGI handlers or keeping an interpreter ready for code input at all time, but to keep thing simple, it's not too far from reality to say we're going to create a new process for every request.
Java and NodeJS would, on the contrary, keep a resident process in memory although they differ in how they handle requests in that process (some will create threads for new connections, others will use an event loop model) and that is added complexity that will have to handled by your app. A benefit of PHP is that you don't need to worry about that.
However, because of the process staying in memory, a Java, Python (Python usually has a different execution model but let's ignore that for the sake of argument here) or Node app could open a few database connections in advance (this is pretty much the concept of connection pools) and keep them around to reuse when clients connect to the app.
A PHP app cannot open a few database connections in advance. It has to re-open connections for every requests or use some third party service (that would keep a process in memory for that purpose).
To summarize, the PHP execution model is the source of several weaknesses inherent to PHP apps:
- Cannot keep a global context or information in memory to be reused between different client requests
- No database connection pooling
- Complex asynchronous operations (e.g. not just reading a file) are very hard to do — which is the reason why many PHP projects also use batches that you have to configure as scheduled tasks using cron or any equivalent
- Configuration, class initialization, code and library imports, database connections, etc. have to repeated for every single request
Although keeping a global context in memory is not possible natively with PHP, it's patched up by other software. It's very common for Redis or memcache to be used alongside PHP to keep information in memory (cache, sessions, ...) in between requests.
However the last point above is a very glaring issue that makes PHP very ineffective even though it's somewhat alleviated by interpreter features such as the opcache.
The Redis solution is also far from perfect. It leverages the great power of that software, but what if you only need to keep a small structure between requests? Going through Redis at every request is not completely free, any socket operation (or file reading, for that matter) is considered very slow from the point of view of a CPU and causes context switching.
That being said, not keeping a process in memory for the application is not only a source of disadvatages, there are some benefits:
- Your app is pretty much immune to memory leaks (the web server and CGI handlers are still susceptible to them, though)
- Since everything is isolated by design, PHP scales very well horizontally (on multiple servers or containers)
- No thread-related issues (race conditions, etc.)
- Hot deployment is possible — There are no services to restart when you update your app it's just the matter of updating the code (assuming it's stable) — This makes it possible to do very simple rolling updates using a versioning tool like Git with no downtime
- Your app cannot crash — meaning that if an individual PHP process does crash it has no direct bearing on subsequent executions (web server and CGI handlers can still crash, although these usually are very stable software)
In practice, when a PHP app has to handle a lot of traffic, its ineffectiveness in having to initialize the same things over and over again will show one way or another. Even considering how easy it is to scale in theory, it still incurs concerns with session handling and more importantly, infrastructure costs.
How does all that tie in with the current article? Well just imagine having to load a huge ORM system that you don't actually use for each and every client requests. You load it, process the request, send the response to the client, ditch everything. Rince and repeat.
Just as in JavaScript, the PHP interpreter has to fly over the complete code before it can actually run it (assuming it's not cached as precompiled). The longer that code is, the longer it takes, even if the part that gets executed is actually just outputting "hello world".
PHP frameworks come with a set of base features including templating and usually, an ORM to get you started quickly.
At some point there were "micro-framework" versions of Laravel and Symfony to try and have a slimmer model to load for every request. The current tendency seems to be about ditching these projects and just use the normal framework but with the smallest set of features.
What if we just made our own sort-of-microframework?
Specifications
Let's lay out what we'd like to have:
- As few dependencies as possible as a baseline
- Static assets bundling
- Some sort of dev server to quickly test on any development environment
Static assets bundling
Static assets bundling is actually not a base feature of any PHP framework, you have to research how to piece that in or configure one of the possible ways provided by the framework itself (example for Symfony).
In my opinion it should be a base feature. Not to become obsessed with web performances like some people are, but we should strive to keep a small amount of extra resources that have to be downloaded alongside our web pages at least until HTTP/2 becomes generalized but even when it eventually does, minifying JavaScript can give a significant advantage in download size depending on your app (not to mention it reduces parsing time for the interpreter).
These are not the only advantages we'll get from using a module bundler, we also get:
- CSS pre and post-processors
- JavaScript modules: can use npm, import and export module versions of your code
- JavaScript minification
- Static assets caching and cache busting (different versions of your static assets will be named differently so that end users always have the very last version of your static assets)
- You can easily inline resources such as html code or small images in your JavaScript by just importing them
- Very easy to do code splitting (discussed later on)
We're also going to use npm as a command line tool to start the dev server and build the static assets for production.
What if I really don't want to use a module bundler?
You don't have to.
Static assets such as JavaScript and CSS are being imported in the partials used by views. You can just replace what we use in src/views/templates/header.php and src/views/templates/footer.php by static paths, relative to the public directory as your static assets absolutely need to be accessible from there.
If using the module bundler as we configured it, the static assets should automatically get created or copied to public/assets.
You'll find more information about how bundled assets are imported in a later section.
Dependency management
PHP frameworks are installed through Composer, which also acts as a dependency management system for PHP addons to the frameworks.
We chose to not use one ourselves. Not because Composer is bad, it's just that I almost never install any extra element using it in my Symfony projects bar maybe for a mailing module now and then.
We're using a dependency management system for Node since we use it to manage static assets, so why whould we not add Composer while we're at it?
It's mostly personnal choice, and adding Composer and some kind of autoloader in public/index.php should not be an extremely time consuming endeavor.
In practice, we find that PHP has a lot of features built in the language, whereas you'd have to install a package to do something as simple as a sha1 hash in JavaScript.
Moreover, features such as database drivers are very often compiled extensions in PHP and not packages as they would be in the JavaScript world and these are not installed through Composer anyway.
Project repository
In case you'd want to follow along for the next following sections, the code for the template project discussed in this article is available at the following Github repo.
Application structure
The directory structure won't surprise you if you're already familiar with PHP frameworks.
We basically want to expose a single directory on the web server, and have all of our source files one level higher, not accessible from the web server (but accessible from PHP).
We're going to call that directory public. Here goes the basic directory structure:
- assets — Holds the images directory, which is copied to an assets directory in public by the module bundler
- public — We touched on it before, public contains the single entry point for our entire app: index.php; it will also contain any file you would want at the web root and the static assets processed by the module bundler
- src — Where most of our PHP, JavaScript and CSS code will live
When using a PHP framework, it's extremely rare to have any reason to touch the PHP files that are in public and it's advised not to do so anyway as these are part of the framework and could be changed by a later version.
We're a little more flexible as we're in full control of the whole process but it still holds true that the majority of our development work will not be inside the public directory but in the src directory, which comes with a structure of its own:
- api — Holds API endpoints handlers, if any
- conf — You can put your config files in there. The project comes with one that gets imported in public/index.php and is just a buch of define statements, keeping things simple
- js — Holds the JavaScript for our app. Two files are required by the bundler to be there:
- vendor.js — This is where we import all the libraries we want to use, with require or import statements (e.g. Bootstrap)
- app.js — This is the main entrypoint of the module bundler and where you should group all of your own JavaScript code and business logic - Your CSS files have to be imported here as well (see existing code)
- lib — You can put whatever you want in there, starts out with a small PHP file used to help with native PHP templating
- styles — Write your CSS resources in there - you still have to import them in app.js (or link them together in some other way)
- views — The different routable views of your app. Also holds a templates directory with the partials
Project requirements
The project dev server requires both Node.js (v10+) and a locally installed PHP runtime.
The PHP interpreter can be installed on any platform including Windows. You should make sure that the php executable is included in the PATH environment variable.
Installing the dependencies
Open your favorite command line in the project directory and run:
npm installYou should now be able to start the dev server using:
npm run devAnd access the app on http://localhost:8081.
Explaining the application entrypoint
Everything starts with index.php to the extend that it should be the fallback resource configured on your web server, so that any request to a file that doesn't exist will default to calling index.php, which in turns has its own 404 handler (it's included in the app).
To do this on Apache 2.2+ you can just add the following directive in your Virtual Host definition (top-level):
FallbackResource /index.phpTo achieve the same result with Nginx, you will want to use the try_files directive to decide what file to serve and will allow you to set a fallback resource last in case nothing is found to fullfil the request.
The role of index.php is simple: decide what to do according to the request URL. That's it.
To make this work we had to implement a certain URL logic that you're completely free to modify to your liking. Just keep in mind index.php should not get too crazy as its processed for every single request and its small size is a big part of the performance advantage we get for not using a framework.
URL and routing logic
As a design choice we have two separate routing logics in place: one for views and one for API endpoints.
Views
To access views in the simplest of cases we look for the following pattern:
/view_name.htmlWhich will just look for a PHP file called view_name.php inside src/views. The 404 view will be loaded in the event that the file doesn't exist.
What if we want to use parameters? We got that covered too. The pattern with parameters would look something like:
/view_name/param1/value1/param2/value2.htmlDo note that the trailing ".html" is still there and is always the very last thing in the URL.
Such a URL would result in storing two parameters in a global variable accessible in $app['url_params'], which means that, in view_name.php, we'd be able to do the following:
echo $app['url_params']['param1']; // Outputs 'value1'
echo $app['url_params']['param2']; // Outputs 'value2'
Let's say you have a page listing blog articles called articles.php with pagination. You could use URLs that would look like the following:
/articles/page/3.htmlWhich is, in my opinion, nice and clean, and semantically indicates we will be sending presentation code (HTML code, that is) from the server.
Some people think it's useless extra clutter but I think it's interesting information about the nature of the response that will help me clearly differentiate views from API endpoints that return JSON or XML or anything else. This is, again, a matter of taste.
API endpoints
The URLs for API endpoints is going to also include the API version string, and, as mentioned previously, we're leaving out the html extension since we won't be returning HTML content.
We could end up with something like this:
/api/v1/api_handler- We're using the leading /api/ as a mandatory indicator that we're looking for API endpoints.
- It should immediately be followed by a version string. Which could just be a number, or something more complex (e.g. v1_2beta).
- The next part is the name of the PHP file that we'll look for in src/api; we will route to a 404 error if the file doesn't exist — We're using the 404 from the views folder but you could create one in the src/api folder that actually returns JSON, XML or no body content at all as headers can be enough information for errors.
To provide params we use the same logic as we did before for the views with something like:
/api/v1/api_handler/param1/value1/param2/value2Which again provides us with the two params available inside the API handler PHP file.
The project includes an example API handler called example.php that holds this simple code:
<?php
header('Content-type: application/json');
// We have access to URL params in $app['url_params']
// and can wire different responses according to that.
echo json_encode(
[
'hello' => 'world',
'api_version' => $app['api_version'],
'params' => $app['url_params']
]
);
if you have the test server running you can try it out yourself:
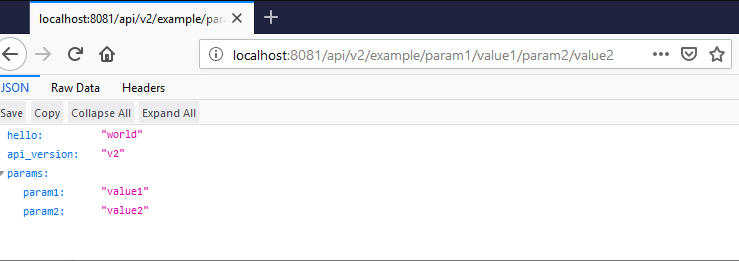
You can structure your API endpoints handlers however you'd like to manage different API versions and endpoints being called by looking up for the presence of certain keys in $app['url_params'].
Templating
We're not using a templating engine. PHP was created from the beginning to go alongside presentation code.
Many developers still think the principle of separation of concern to be very important.
The concept itself diluted in some way with the introduction of technologies such as React and poses the question of trying to assess if what we're separating really are different concerns.
Unpopular opinions set aside, we're not talking about creating a directly routable contact.php file strung together with HTML intertwined with database requests and huge sections of presentation code inside if statements but you're going to be the arbiter of how orderly the code of your views will be.
In other words, you get more control and use what is already available in the language (some people like to say "Use the [web] platform" to convey a similar message).
Other people will consider this dirty and to be honest we do lack having some sort of caching mechanism that most template engines have, and access to a single output render function call that does make things cleaner.
In the end you can just as easily add the template engine you prefer to the project.
In my experience there are two things that seem to hold true:
- You never reuse templates from a project to another or they require so much adaptations that just having the partials is fine (praying that you don't have to go from HTML/XML style to something like Jade);
- The lack of control over the cache mechanism can actually turn it into a hindrance, and the performance difference is very small (we can't keep things in memory, remember? And reading storage is a blocking operation!).
So how do we propose doing templating?
We provide a way to include partials and make variables directly accessible in them. You then have access to a handy shorthand way to output the content of a variable inside the partial with native PHP, as in:
<title><?=$title?></title>PHP provides similar shorthand ways to write loops and conditions, which basically amounts to not using the usual {} brackets and writing something like:
<?php if ($someVariable): ?>
<p><?=$someResultToShow?></p>
<?php endif; ?>
All of that is native, you don't need any library or template engine.
In src/lib/Templating.php you will find the following short static function:
public static function includeTemplate($filename, $vars = array()) {
if (isset($vars)) extract($vars);
include(dirname(__DIR__) . '/views/templates/' . $filename);
}Where we just use extract to make the keys and values of the $vars associative array available as plain variable in the partial. We then include said partial.
Linking the compiled static assets
We're using Webpack to bundle the JavaScript and CSS for us into a set amount of files that are named using their content hash, so that these files can be safely cached indefinitely by browsers since their name will change when we make modifications to them.
Webpack configuration can be particularly daunting but the included webpack.config.js should do its job well enough out of the box.
It's configured to output a manifest file that can then be read by PHP scripts so they can find out the names of the static assets to import them.
In src/lib/Templating.php there is a function called getAssets that does just that and returns an object with the assets as keys.
If you look at the example view src/views/index.php, you'll see it's providing this object to both the header.php and footer.php partials, which respectively use the variable like so:
<link rel="stylesheet" href="<?=$assets->{MAIN_CSS_BUNDLE}?>" /><script src="<?=$assets->{VENDOR_JS_BUNDLE}?>"></script>
<script src="<?=$assets->{MAIN_JS_BUNDLE}?>"></script>We do it that way because we chose to import the CSS in head and the JS at the end of body.
The constants MAIN_JS_BUNDLE and MAIN_CSS_BUNDLE are actually set in src/conf/config.php to match the names of assets in manifest.json as defined in the Webpack configuration file.
How to include static assets
Webpack looks at the entrypoints src/js/app.js and src/js/vendor.js.
Important: All your stylesheets should be imported in app.js.
If you have a look at the app.js file we provide, you'll see it has an import for an SCSS file:
import '../styles/styles.scss';So, yes, as an added bonus we're immediately using SCSS out of the box which is something that would take you some time and knowledge to put together using a PHP framework.
Of course you don't have to use SCSS, you can also just import any regular .css file in app.js and that would also get bundled into a single resulting CSS file.
You can easily create more entrypoints to have more code splitting for your application and, for instance, only load the JavaScript (and CSS - if any CSS is imported in the entrypoint) for your blog section on the actual blog section views. Just add more entry points in the entry object of webpack.config.js:
const config = {
entry: {
app: './src/js/app.js',
vendor: './src/js/vendor.js',
blog: './src/js/blog.js'
},
// Rest of the Webpack Config
};
Webpack will now create a new JavaScript bundle based on "blog.js", and you'll be able to import it in your views (NB: you have to do this manually in your header, footer or any other adequate partial) and partials by finding it in the JSON manifest file at the "blog" key.
Adding more code splitting can make your app even faster as you limit the amount of JavaScript and CSS that you load on the first pages your users will visit.
Performances
We were curious as to how it would measure in terms of performances as compared to Symfony.
We picked Symfony to test against because it's the most used Framework in our customer base but there's good chance the results would be similar with Laravel since these two are have been in competition for a long time and draw from each other all the time.
Test setup
We created a base Symfony project like so:
composer create-project symfony/website-skeleton bench-symfonyBoth Symfony and our lightweight project use a single-point of entry PHP file, which is their public index.php file.
The whole process involved for every single request starts and ends in that file making it the perfect place to put some quick timing information.
Done as roughly as possible we modified Symfony's index file like to:
<?php
$start = microtime(true);
use App\Kernel;
use Symfony\Component\Debug\Debug;
use Symfony\Component\HttpFoundation\Request;
// ... MORE SYMFONY STUFF
$kernel = new Kernel($_SERVER['APP_ENV'], (bool) $_SERVER['APP_DEBUG']);
$request = Request::createFromGlobals();
$response = $kernel->handle($request);
$response->send();
$kernel->terminate($request, $response);
echo 'ELAPSED ' . (microtime(true) - $start) * 1000;
We then picked Docker for the test environment and used this very simple Dockerfile for both projects:
FROM php:7.3-apache-stretch
COPY . /var/www
RUN rm -rf /var/www/html && ln -s /var/www/public /var/www/html
WORKDIR /var/www/html
EXPOSE 80
CMD ["apache2-foreground"]
We initially disabled opcache in the Dockerfile. But it appers that enabling or disabling opcache (with its default value, we haven't tried customizing opcache) doesn't have any impact on the results.
That would warrant more exploring but we left it at that for now.
Both test project produce the same "Hello world" page that uses two template partials in a main layout template. The Symfony dev mode has been completely disabled.
Symfony comes with the Twig template engine out of the box so we're using that on the Symfony project. Our project comes with Webpack assets bundling and the manifest reading out of the box so we kept it too.
Benchmark results
We collected a number of samples from refreshing the index pages for both projects on the same host machine and computed the average time to process the PHP file from beginning to end.
We got the following result in average processing time (milliseconds), lower being better:
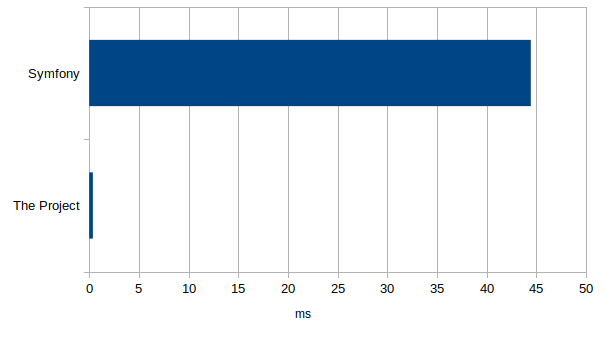
Where "The project" means the lightweight workflow this article is presenting.
It's apparently about 118 times faster than Symfony. We expected it to be faster but not on that order of magnitude.
We also tested requesting the index resource with command-line curl to see how that one goes with the extra network request response time added in and if that shows the same values PHP shows us, and it does but closes the gap a little bit:
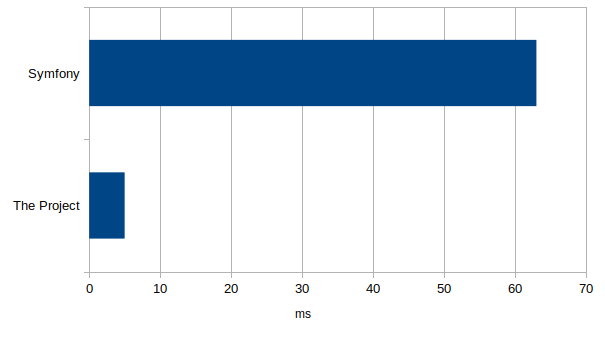
In the curl test, Symfony only performs about 13 times worse which seem to show that adding the network layer has minimal impact on how Symfony performs, probably because a part of the processing happens in parallel to sockets blocking operations.
The difference is still massive. Especially since, due to its execution model, the performance drain is effectively multiplied by the amount of concurrent requests you're projecting to have.
While this test was performed on a M.2 SSD, it's possible that we'd have closer results using memory storage (ramdisk or else).
The disk reads and the amount of code to parse are probably the sole reason for the performance gap, even though our project also has to read the manifest JSON file (and parse its JSON) for every requests, but that doesn't seem to matter much.
Keep in mind Symfony has recommendations to optimize projects for production that we did not follow. The idea was to see how it went baseline by just creating a project and getting going.
In case you want to share any idea about how to possibly close the gap, we'd more than welcome that and showcase anything tangible in here.
Shortcomings and possible improvements
There's a lot of improvements that could be made to our simple baseline project.
Here are a few of its shortcomings and possible improvements to be made.
No caching
The absence of caching has been discussed several times before in the current article.
Most template engines use some sort of caching.
For now, we're opening the Webpack manifest.json file for every request, parsing it, then using the values to generate header.php and footer.php.
Parts of all this could easily be cached somewhere, as manifest.json doesn't change very often. Some partials could also be cached.
At a certain point and with certain workflow, the entirety of your app performance might be dictated by the effectiveness of your caching mechanisms.
This is so important that I actually think it's a good thing to not have built-in caching and have to think about it case by case.
However, in most serious applications, you'd end up needing some form of it. Be it in files, Redis or equivalent, or any database system really.
For small applications, it tends to be a source of hard to debug inconsistencies and more disk or network blocking requests.
No transpiling
Modern JavaScript code tends to be ES6/ES2015 which browsers such as Internet Explorer 11 and older do not understand at all. More importantly, the current Google Bot has no ES6 support either.
This means that if you want to use JavaScript libraries written in ES6 or use ES6 yourself, you're going to need transpiling.
You can easily fix that issue by adding Babel as a loader for .js files in the Webpack configuration and then using a Babel preset ("env" is fine).
As a personnal choice, I prefer to not have Babel present as a base requirement.
There are plenty of articles online about how to add Babel support to Webpack but in case the subject is interesting to some people we might add explanations in the project README.md — let us know in the comments below.
CSS minification and autoprefixer
We're not doing CSS minification at all and autoprefixer is only enabled for SCSS files.
This requires a little bit of work on the Webpack configuration.
Add a Dockerfile
Testing the app with the PHP dev server is fine for small workflows, but the general performance is pretty bad and you also need to make sure to have all the PHP extensions needed by your app locally installed on your dev machine, and the process of installing or enabling extensions is not the same depending on your development platform (Windows, Linux or Mac) - a few extensions even behave differently depending on the platform.
We would then need to make sure to have the same extensions in the production environment.
Using a Dockerfile to describe that environment and possibly use it for testing and production just as well could be a great thing to add for consistency, although a nice thing about our project is that it should be simple enough to work on many different production enviroments with no intervention.
No tests
There is no test logic available right now whereas testing is something built in the main PHP frameworks.
Tests are important and can be done in a lot of different ways. I tend to prefer setting in up in JavaScript as we have access to a ton of great projects such as Puppeteer and Jest but that's up to you.
No fancy dev mode
PHP frameworks provide you with profiling and debugging information in their "dev mode".
I find out that I personally never use these features. If I need profiling I add it myself directly in the code on some test branch of the code repository.
I can understand how some people could miss it, though.
Conclusion
We hope to have illustrated that you don't necessarily need a framework to benefit from a modern PHP architecture with features such as static assets bundling.
The workflow ends up being much clearer and boots up faster.
It's far from perfect and in no way should replace frameworks, but we hope it took you back to simpler times, as it did to us.
The current website is using a similar application structure and at the time and ended up being the easiest way to incorporate legacy code from the previous versions of our website.
We also found strong evidence that not using the Symfony model in particular, proved to be much faster in execution time (118 times faster!).
Which makes me think twice about how to implement a quick REST API backend. PHP frameworks have the reputation to be pretty fast for that kind of use case in such an extend that we no longer need "microframeworks", but is that really the case if you look closer?