Introduction
Over the years the concerns over security have changed drastically and progress was made by having more homogeneous web browser standards.
The unfortunate consequence of that is that these standards have become very convoluted with parts that appear to be redundant and a lot of baggage.
Let's go through a few of these security mitigation headers and the rules they follow.
Most of these security measures involve sending specific HTTP headers from your application/website.
We'll try to touch on ways to do this from the most common web servers/reverse proxies (Nginx, Apache and HAProxy) in a separate article, the current one will be a descriptive tour of the most useful HTTP security-related headers — Not easy to digest but that you could keep aside as support for the upcoming practical article, would you be more practically oriented.
Frames security
The iframe HTML element is infamous for being linked to a variety of different possible attacks, including DDOS, clickjacking (was very common with Facebook and you liking a page you never formally clicked on) and more.
Browsers will look for a header called X-Frame-Options in the server response to the request to the iframe URL to decide whether they allowing the iframe content to be displayed or not.
You can use one of the following values to prevent your site from being put inside of an iframe on other websites, or just prevent it from being put inside an iframe anywhere, ever:
X-Frame-Options: DENY
X-Frame-Options: SAMEORIGINThe first value (DENY) effectively prevents the page from being put in any and all iframe contexts, including on your own site. Second only does it for sites that do not share the same origin as the target URL.
The concept of Origin comes back quite often, it's defined as the current protocol, host name and port number.
For instance, the Origin part of https://www.net7.be/blog/article/blocking_git_svn_http.html is https://www.net7.be:443, the port is assumed to be the default port for protocol HTTPS, which is 443.
The X-Frame-Options headers is very common and usually has the SAMEORIGIN value. For a smaller applications, you can probably safely use DENY.
Content Security Policy (CSP) header
The Content-Security-Policy header is meant to tell browsers that they can only get external resources from a specific list of URLs.
HTML tags that access "external resources" include img, script, link, audio, video and more. You get the idea.
A typical attack vector would be to try and inject HTML code to a target website, for instance through a comment form that strips some HTML tags but does not strip the script tag because the authors forgot about it (which is obvioulsy a gigantic security flaw by itself but bear with me) — It's possible for an attacker to inject their own script from their own malicious website and clients visiting your website will execute that script, possibly stealing session information, displaying unwanted content or making malicious requests to some website to attempt bringing it down.
Other than fixing the giant security flaw that is not stripping the script tag, that attack could be blocked by only allowing the script tag to load content from the current website and nowhere else which is the purpose of the Content-Security-Policy header.
The easiest way to use it is as follows:
Content-Security-Policy: default-src 'self'Where the value default-src 'self' means the browser should never try to load any kind of resource (including in AJAX requests and form actions) from anywhere but the current origin — which we defined above in the X-Frame-Options section — and per-definition excludes subdomains.
Such a policy is quite restrictive as it will also completely prevent you from, for instance, loading an image from another website in your HTML or CSS code.
Fortunately we can add a list of authorized sources instead of just the special value 'self':
Content-Security-Policy: default-src 'self' *.trusted.com someotherdomain.orgWhere wildcards are allowed and just using the wildcard character (*) alone would technically be the oppositve of 'self'.
Here we allow loading content from the same origin as well as any subdomain of trusted.com, and someotherdomain.org.
It's recommended to always at least provide default-src but we can always set different rules for a specific type of resources. For instance, have a look at the following rule:
Content-Security-Policy: default-src 'self'; img-src https://*;That policy only allows loading content from the current origin except for images, which can be loaded from any https origin.
Each type of content and its list of allowed origins are separated by semicolons.
Additionally to the special value 'self' there's the special value 'none' which completely blocks loading that type of resources, see the comment about frame-src below.
Resource types
Here's the list of the different types of resources for which you can set a specific policy:
- default-src: The only technically mandatory one, default value for any policy not explicitely defined
- connect-src: Controls AJAX permissions, mostly
- frame-src: Sets what's allowed iframe and frame tags URLs — You could use the special value 'none' if your site is never supposed to host any kind of frame tag
- img-src: Controls img and picture tags sources as well as the favicon, does not affect the CSS property background-image
- font-src: Limits font import sources in CSS
- media-src: For the audio and video tags
- manifest-src: Specific to the meta tag declaring the application manifest
- object-src: For the tags object, embed, applet — as these are legacy tags it's recommended to use 'none' as the policy value for this one
- script-src: For script tags
- style-src: For CSS imports though the link and style tags
- form-action: Affects allowed URLs in form actions
Inline styles or scripts
There is an important caveat with script and style tags when using a CSP header in that it won't allow you to use "inline" styles or scripts by default.
Let's say you're using this very simple policy:
Content-Security-Policy: default-src 'self'And this is the HTML code sent by your server:
<html>
<head>
<link rel="stylesheet" href="styles.css">
<style>
body {
background-color: orange;
}
</style>
</head>
<body>
<h1>Welcome to my website!</h1>
<script>
// Some inline code
console.log('Hello from inline code!');
</script>
<script src="main.js"></script>
</body>
</html>The browser will load styles.css and main.js but will completely ignore the style tag with the red background and the console.log in the first script tag at the end of body.
To allow these "inline" script or style tags, we have to use the special value 'unsafe-inline', so that would work:
Content-Security-Policy: default-src 'self'; script-src 'self' 'unsafe-inline'; style-src 'self' 'unsafe-inline'Do not forget to still add 'self' or only "inline" styles or scripts will be allowed.
We can make a shorter vesion by adding the 'unsafe-inline' in the default policy:
Content-Security-Policy: default-src 'self' 'unsafe-inline'Keep in mind that allowing "inline" scripts is potentially dangerous as script injection is often done inline, so if you can work without 'unsafe-inline', you should and that would be the best practice: limiting scripts to loading them from the same origin, no inline allowed.
Finally, let's just state the obvious in that none of these security headers will make your application bullet-proof. For example, the British Airways hack was made by injecting a script on the actual trusted website server.
Preventing that level of tampering is another story entirely.
Using a meta tag
It's possible to use a metatag instead (or additionally) to the HTTP header.
Doing so is intended for cases when you have no (or limited) control over the server software or some part of the backend where you'd need to inject the headers.
If you have CSP information in both the HTTP headers and a meta tag in the head part of the document, the browser should combine them if applicable and use the most restrictive options when there's a conflict (e.g. both policies having img-src but one of them being more restrictive: that one gets applied).
Combining the two could yield unpredictable results and as such it's probably better to stick to one or the other, with the headers being the preferred way.
Reporting
Browsers can be told to report any violation of the CSP policies to a specific remote server which will receive a POST request with JSON content.
Uisng it requires you to setup a backend service that will process and record the reports. It could be useful for auditing but anyone could technically flood tons of fake reports.
We suggest reading the MDN docs about reporting in case it picked your interest.
The Feature-Policy header
The Feature-Policy header informs browsers about disallowing specific parts of the DOM API.
For instance, you could always block geolocation on your site by adding the following header:
Feature-Policy: geolocation 'none'We won't go into much details for the Feature-Policy headers because if you're already blocking inline scripts and scripts from outside and also not using iframes, there's no chance for geolocation to be abused anymore (if we take the geolocation example).
More importantly: it's still experimental and is being renamed as Permissions-Policy as the time of writing this article.
It's base use case as of now is controlling what is allowed in iframe content.
HTTP Strict Transport Security (HSTS)
The HSTS header basically means you want browsers to only visit this site using HTTPS and thus having authentification of the remote party and encryption of the content.
The header always has to contain a value called max-age. Browsers will keep the HSTS status of the websites you visit in their cache for the duration of that max-age value in seconds (unless you clear your cache before, of course).
It can also have two optional flags:
- includeSubDomains: means the browser will also enforce HSTS for any subdomain of the current domain that you'd try to access. If the domain where HSTS is enabled is a root domain like "company.org", the browser will demand HTTPS for every single subsite of "company.org" that their user visits during the validity of the HSTS policy (as defined in max-age) — Keep that in mind when using a root domain as your website URL;
- preload: Google maintains a list of domains on which HSTS should be applied right away, even before querying the server. You can request to get added to that list, and that requires the “preload” attribute to be in the HSTS header from the server responses.
Here's an example with everything set:
Strict-Transport-Security: max-age=31536000; includeSubDomains; preloadWhere 31536000 seconds is about one year (it is one year, I'm adding the "about" to be rigorous as the amount of seconds per days and years can technically vary).
The value 63072000 (about 2 years) is also often seen.
Before enabling HSTS (which is rumored to help in SEO but don't quote me on that and it's probably weighted pretty low) it's a good idea to make sure the certificate is perfectly valid all the way using an SSL checker tool and you have your automatic renewal working or renewal reminders set because you won't be able to just ditch HTTPS for some time once it has been cached by many clients.
Also keep in mind the remark about root domains and includeSubDomains, as including the subdomains could effectively lock out some internal or legacy subsite of yours that do not have HTTPS support.
Referrer security
The Referer header is anything but new in the HTTP spec.
In case you don't know what it does, browsers (and many HTTP clients in general) will add a Referer header containing the URL of the current website to requests to any resource that the aforementioned current web page demands.
This includes images, scripts, etc. and more importantly, links (<a> elements).
As an example, let's say you click the following link to Wikipedia.
The server at wikipedia.org will recieve your initial HTTP GET request with a Referer header present, that could (I say "could" because referrer secutiry headers — the object of the current section — can change this) read as follow:
Referer: https://www.net7.be/blog/article/xss_csrf_http_security.htmlYou may have noticed different spelling in how the Referer header is described. The correct spelling is "Referrer" with two Rs but it was registered as "Referer" in the HTTP spec and was kept as such for historical and compatibility reasons.
The Referer header can simultaneously be used to increase security on the backend, and cause security issues on the client side.
Referrer in CSRF prevention
Let's examine the first case: preventing cross-site requests.
Let's say you're logged in on your (poorly made) banking website and have checked "Remember me" so that you don't have to enter your credentials everytime.
Your browser is keeping a session cookie that it automatically sends alongside any request to the banking website domain name (if it meets the cookie scope but let's say it does).
A malicious third party creates an innocent looking website with a hidden form which can be submitted with JavaScript (or clickjacking, or other ways actually) and posts to your banking website, something like:
<form action="https://yourbank.com/transfer" method="post">
<input type="hidden" name="to-account" value="HACKER-BANK-ACCOUNT-NBR" />
</form>Submitting that form will cause your browser to send a POST request to https://yourbank.com/transfer with the session cookie attached to the request, and the server will thus accept the money transfer.
Obviously just having some extra step asking for confirmation or better cookie security or an anti-forgery token system (often transparently included by server application frameworks like Django or .NET MVC) would just make this attack impossible, but moreover, it can also be stopped by checking the value of the "Referer" header on the server side.
If the request is not coming from the actual banking website, that will immediately show in the Referer header (its absence should also be considered abnormal - The POST should always come from a deliberate click from the banking website itself) so that you can check for it and decide to accept or refuse the transfer on the server side.
Let me mention that checking the Referer header as the sole mean of cross-site request defense is not recommended and is often seen as a legacy security measure, because browsers could technically decide to completely remove the Referer header by default at some point because it's seen as a threat to privacy — which we'll discuss in the next section.
Referrer as a privacy/security issue
By default the Referer header contains the full URL of the calling page, including the query part (e.g. "?somePrivateInfo=yes&etc=no").
That query part in particular can contain identifying information that could help track sessions, identifiy a specific customer or its behavior (an advertiser could track that you made a request coming from the shoes section of a shop, which means you should be shown more ads for shoes) or even sometimes steal sessions as there was a time when the equivalent of a password could appear in the URL. It sounds preposterous but could still happen by mistake even in enterprise applications.
Web servers can also log the Referer headers which is very interesting for stats but also means sensitive information (sessions/passwords) could end up in these log files and you may not tightly control who can read or leak them.
The best practice for designing applications URLs is to have them carry the least possible user-identifying information and try using a POST body instead. These practices do lessen the threat level.
Controlling what browsers send in the Referer header
I tried to demonstrate that the Referer header is both useful for stats and server side access control and dangerous for client privacy.
Fortunately there is a way to try and get the most out of it through an HTTP header called Referrer-Policy.
Possible values are:
- no-referrer-when-downgrade: The default behavior in most browsers at this time (it could and probably will change) and means to not send a Referer header when there is a protocol downgrade (HTTPS → HTTP); Sends the full URL otherwise (reminder: includes the query part)
- no-referrer: Never send the Referer header with requests coming from the curent site; You'll have to keep in mind it's going to be absent when checking requests on the server-side and that's intended — Safest option for clients but you completely give up an easy window to your website usage stats
- origin: Only send the "origin" part of the URL — Which means same protocol, domain name and port and strips anything else — Makes it so you can keep the Referer header with barebones information in it
- origin-when-cross-origin: Sends the full URL (reminder: includes the query part) as Referer if request concerns the same origin — Otherwise only sends the origin part — Useful to keep better internal customer behavior stats but send minimal information to the outside requests
- same-origin: Sends the full URL as Referer if request concerns the same origin — does not send a Referer header otherwise — Means external websites won't be able to tell where their incoming requests from a link or image is coming from
- strict-origin-when-cross-origin: The same as origin-when-cross-origin except this sends no Referer header at all when there is a protocol downgrade (HTTPS→HTTP) instead of just sending the origin part of the URL — It's considered to be a good “default” starting value (it's NOT the default value though)
- unsafe-url: Will always send the full URL in the Referer header, even in case of protocol downgrade (HTTPS→HTTP) — This is the most permissive options of them all
To illustrate, we could use the following header:
Referrer-Policy: strict-origin-when-cross-originIt's also possible to use a meta tag in case you don't have the means of adding headers at the server side:
<meta name="referrer" content="same-origin">Referrer security inside the DOM
Just as an aside, some tags have extra arguments that can restrict what the browser sends within the Referer header when making requests related to these HTML tags, which would include a, img, iframe, area, link and script.
For most elements you'd use the referrerpolicy argument, like so:
<img src="some_image.png" referrerpolicy="origin">Where you can use any of the values described above and it will have precedence over any higher level referrer policy set by the HTTP header or the meta tag.
For the a element, the older and most compatible way to simply prevent the Referer header to be added is to use the rel attribute like so:
<a href="http://example.com" rel="noreferrer">Classic</a>The referrerpolicy attribute also exists on a elements, it's just a more recent standard and could be ignored by old browsers.
Cookie security
Since cookies are sent as HTTP headers and are often used for sensitive session identification it made sense to talk about them too.
The HTTP header itself is called Set-Cookie when sent inside a server response, and can accept three optional security attributes:
- Secure: Means the cookie header should only be added to requests if they are using HTTPS. It doesn't do much especially with HSTS, but security audits consider it bad to not have it set so it's a good practice to always use the Secure attribute on cookies
- HttpOnly: Usually set by servers — Makes the cookie unavailable to the JavaScript inside the client browser — Any cookie transporting information that the client-side JavaScript has no use for should always be set to HttpOnly (typical for server session cookies) — Browser will still attach relevant HttpOnly cookies to AJAX requests made with JavaScript, it's just that JavaScript itself can't see the cookies
- SameSite: Discussed in a later section as it's a little more complex than the others
Cookies should also have an expiration date that makes sense for their use (defaults to browser session duration) and can be set either as a number of seconds (max-age=64000) or a specific UTC date of expiry (expires=Tue, 19 Jan 2038 03:14:07 GMT).
When are cookies sent?
Cookies have the scope-limiting attributes domain and path which respectively default to the current domain for the server and "/".
Let's just state the obvious for now just in case: you cannot ever set a cookie to a domain that is not either the one you're currently on, or a higher level one. It's impossible for microsoft.com to set a cookie that would be valid on apple.com. That rule probably makes sense to most people.
Web browsers will keep cookies sent by the server and send back their values to the server (values only, no expiration, security policies, domains, paths or whatnot), using the Cookie header, to further requests that match the cookie domain and path (if the cookie isn't expired).
When multiple cookies apply, browsers just concatenate all their key value pairs with semicolons in the Cookie header of the request.
Now the thing is they will also send the cookie for subdomains of your site, for instance the cookie for example.org will also be sent to forums.example.org. Or will it?
First: not if the cookie was not explicitely set with a domain= value in it that matches the higher level domain.
Any cookie that was set without a domain= value is never sent to any subdomain. It might be that it was in the past (the information is very hard to find) but now browsers never send a cookie to a subdomain if it wasn't explictely given a domain= value that would allow it.
Even if the higher level domain was present in the cookie, there's an extra layer of complication in that some domains are evidently independant even though they could logically have a domain/subdomain relation.
For instance, let's say you're logged into https://favoritehoster.be for free static website hosting and they decided to provide ;domain=favoritehoster.be; as part of their session cookie — That session cookie for that site could technically also be sent to my-blog.yourfavoritehoster.be and your-blog.yourfavoritehoster.be even though that could be a security issue because these have completely different owners.
To solve the issue, browsers maintain a list called the Public Suffix List which identifies top level domains (they should all be in the list: .com, .org, etc.) and lower level domains that "resell" parts of their domains to independant websites.
Another example of this would be github.io as they offer web space for your projects on subdomains of github.io, e.g. my-project.github.io should be completely independant from your-project.github.io and none of these sites should get cookies from github.io nor be able to set cookies that could be sent to github.io (which is actually not used as a website but you get my point).
This is enforced by the public suffix list.
As an aside: Because having cookies automatically sent to subdomains could be a security issue, using "www" in front of your site that uses cookies instead of the root domain would immediately limit that propagation without even having to set the right scoping or any cookie policy discussed below and this is one of the reasons why using "www" was historically prefered even though it fell out of fashion for shorter URLs over time.
The SameSite attribute
SameSite is a cookie property that can have 3 different values (note the starting capital letter):
- None (default value)
- Strict
- Lax (some browsers intend to use Lax as the new default)
As discussed before, browsers keep unexpired cookies around and send them in the request headers when the cookie domain and path matches (alongside other security restrictions, of course).
Meaning that, when you click a link to your Wordpress blog on which you were already authenticated by cookie (as a mean of “keep me logged in”) your browser will recognize your blog domain (and path) and send your persistent session cookie with the request.
Using SameSite=Strict makes it so that this does not happen. The cookie is only sent if you're already on the website (the Wordpress blog in our case) or just typed its address in your browser address bar or clicked your own favorite/history entry from your own browser — Moreover, the cookie is never sent to subdomains either, only if you're already on the exact same site.
Which makes it another way to prevent cross-site requests, as doing a secret POST request from another site to a site you're currently logged in using a session cookie just won't send said session cookie, and so the cross-site request will fail.
Typing the site address in the browser address bar will still cause the cookie to be sent, it's getting to it from a link on another site, having some src or href pointing to it from another site, or having a form post to it from somewhere else that won't send the cookie along with the request.
Using SameSite=Lax still prevents sending the cookie to a subdomain, as Strict does as well. The difference being that Lax allows the cookie to be sent from requests originating from another site, to the site domain and path that is registered on the cookie.
So, the POST request example from above would work with the Lax policy.
Using SameSite=None simply also sends to cookie along to a request to any subdomain (if not prevented by the public suffix list or domain= being absent from the cookie) and is also oviously sent along for requests originating from another site to a valid domain for that cookie.
Important to note: If browsers start using Lax as their default policy, it'll make it much harder for a cookie to be sent to a higher level domain ever as it would require specifically having SameSite=None sent out by the server for these higher scope cookies or they'll stop working.
When setting cookies with JavaScript, Firefox is also issuing warnings that they'll completely ditch any cookie (set using JavaScript) that has either SameSite=None or no SameSite specified and no Secure being present in the cookie.
Setting SameSite=Lax or adding Secure does the job though:
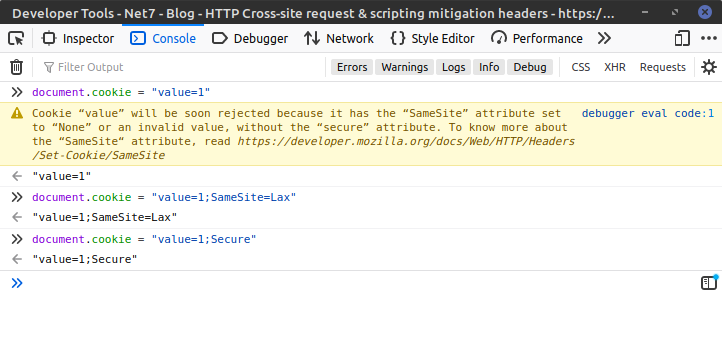
As far as I know, Chrome doesn't enforce anything like that (yet).
In general, any cookie that only makes sense after having done some on-site action (like adding something to your shopping cart) is best used as SameSite=Strict.
If you're still confused about these cookie policies, we suggest reading this other article.
Modern session handling for rich client apps
Just as an aside about cookies, it's sometimes now suggested to not use them at all in modern client-side apps that rely heavily on JavaScript and AJAX requests.
The recommendation would be to use your own token based system that could maybe follow a standard like Oauth and save it in the newer localStorage or sessionStorage JavaScript APIs.
The JSON Web Tokens standard provides libraries to implement asymetric encryption and validation of authenticated messages (which is then on top of the authentication and validation provided by HTTPS).
Would you really want to provide the highest levels of security for rich client applications, you'd probably have to look into complex JWT implementations.
All of that would be a discussion for another time as it's out of scope of the current article and its upcoming part 2.
Conclusion
We went through what we think are the most relevant security-related HTTP headers as for now.
The next article will look into implementing a coherent security policy with practical examples for various server software and backend languages as well as provide suggestions for good starting/default policy values.